2026-02-25
In Search of Consensus: Breaking Down the Raft Algorithm
In Search of Consensus: Breaking Down the Raft Algorithm
If you work in data infrastructure, you've probably heard of etcd, Consul, or the newer versions of Kafka (KRaft). They all share something in common: they need multiple nodes to agree in a world where networks fail.
This post collects my notes on the paper "In Search of an Understandable Consensus Algorithm" by Diego Ongaro and John Ousterhout — the text that made distributed consensus accessible beyond the circle of Paxos experts.
The foundations: SMR and the power of quorum
For a cluster of servers to behave as a single reliable machine, Raft relies on State Machine Replication (SMR). The idea is elegant: if all nodes start from the same state and apply the same sequence of commands (the log), the final result will be identical.
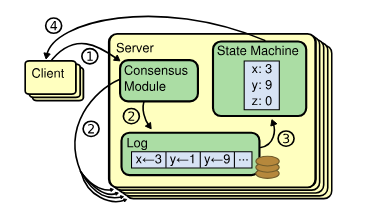
But how do we guarantee they all see the same order in an asynchronous environment? This is where quorum mathematics come in. To make any decision, Raft requires a vote from the absolute majority of nodes ($n$):
$$V > \frac{n}{2}$$
This property guarantees that any two majority sets always share at least one node in common — a "witness" that prevents the system from forking into contradictory decisions.
The state model
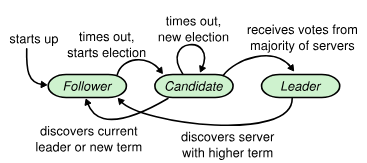
Raft simplifies the problem by decomposing it into three possible states for any node, forming a finite state machine with clear transitions:
- Follower: Passive state. Only responds to requests from the leader or candidates.
- Candidate: Intermediate state. A follower whose timeout expires and seeks to become leader.
- Leader: The cluster coordinator. Handles client requests and coordinates log replication.
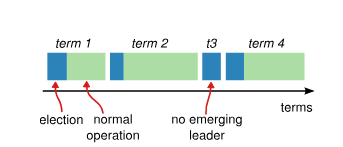
Time is divided into terms, which act as an incremental logical clock ($t = 1, t = 2, \dots$). If a node detects that its term number is lower than another's, it updates immediately.
Leader election: who's in charge?
The election process is Raft's core availability mechanism. It's based on a heartbeat signal. If a follower stops receiving signals from the leader for a configurable period, it assumes the leader has failed and:
- Increments its
currentTerm. - Transitions to Candidate state.
- Requests votes from other nodes via the
RequestVoteRPC.
The split vote problem
If many nodes transition to candidate simultaneously, votes can fragment so that no one reaches quorum. Raft solves this with a simple yet effective approach: randomized timeouts.
By assigning each node a random wait time (typically between 150ms and 300ms), it's very likely that one will "wake up" first, request votes, and win the election before the rest become competitors. Simple and robust.
Log replication: data persistence
Once a leader is elected, its job is to accept client commands and replicate them. This is where the Log Matching Property comes in — a safety guarantee based on induction:
If two entries in different logs share the same index and term, then they contain the same command and all preceding entries are identical.
This ensures that once the leader confirms an entry has been replicated on a quorum of nodes, it's considered committed:
$$\text{entry} \in \text{committed} \implies \text{entry} \in \text{log of all future leaders}$$
Conclusion
What interests me most about Raft isn't its efficiency (which is reasonable), but its design oriented towards understanding. By separating leader election, log replication, and safety into independent subproblems, it allows reasoning about each part without having to keep the entire system in mind at once.
If you're interested in the topic, the original paper is surprisingly readable, and the interactive Raft visualization is an excellent tool for understanding state transitions in action.